Let's Talk DR

When I started writing this piece I had the title as “Let’s talk disaster recovery”. As I thought about it there appeared to be more value in using and exploring the popular term “DR”. Why?
Ask yourself - what is DR? (In the context of business IT systems).
You might find yourself describing a process of recovery or reaching for google - a common reaction.
In most cases people will equivocate DR for Disaster Recovery. Some people will answer with “disaster recovery or business continuity”.
While the inter-changing of disaster recovery and business continuity within conversation will not lead to a conversational misunderstanding - it does imply that the two are one and the same thing. Which they are not.
In order to discuss “what is DR?” let’s consider alternate acronyms for DR.
Desirable Recoverability
When people talk about DR there is often a suspense of disbelief - the kind when you go visit the cinema. An exhibition of a recovery (even in a test condition) is the ultimate example of desirable recoverability. Unfortunately the trap here is one of self-deception. It is possible to equivocate the DR test you just performed to the real deal (the test was difficult, and it took hours to perform).
A test failover in DR is analogous to training matches in football. They are useful exercises to perform but they are ultimately just one way of increasing your preparedness for the big match day.
Test failover scenarios are typically written with easy to understand scopes. An example of which is “entire site failure (with no opportunity to repair)”. This is easy to understand and easy to test. It also appears to be quite a valuable use of time - after all “entire site failure” would be extremely detrimental to any organisation.
Testing only this scenario however addresses only a fraction of failure domains. The truth is you are more likely to have partial failures.
If you have only tested full failover scenarios - then you are only capable of executing full site failover, and ultimately your DR solution will treat every significant failure as a site failure.
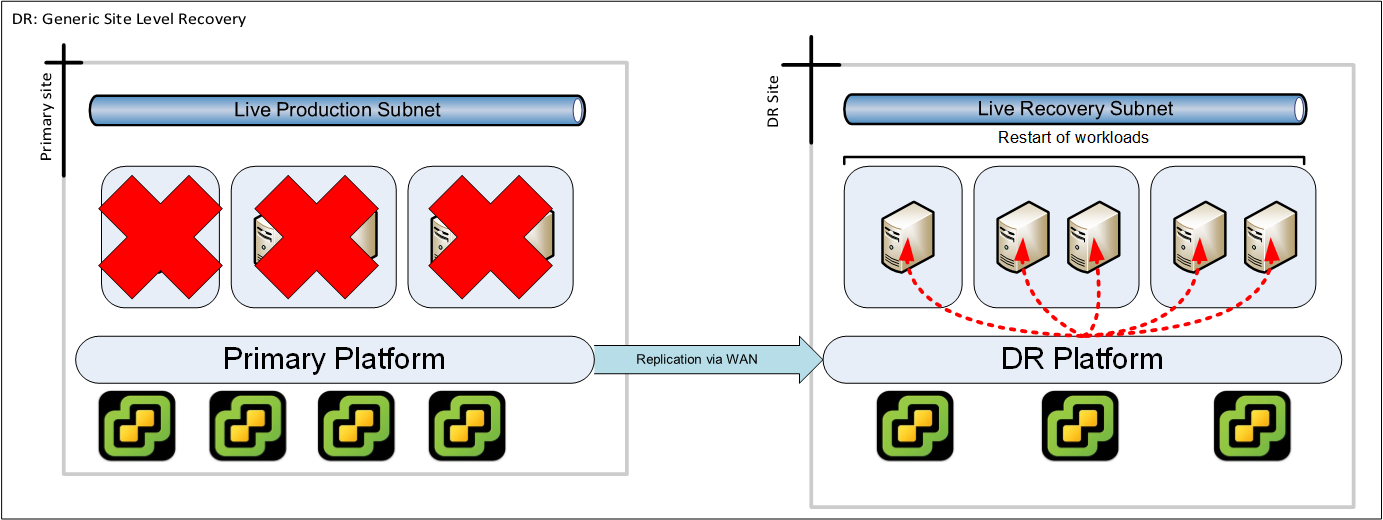
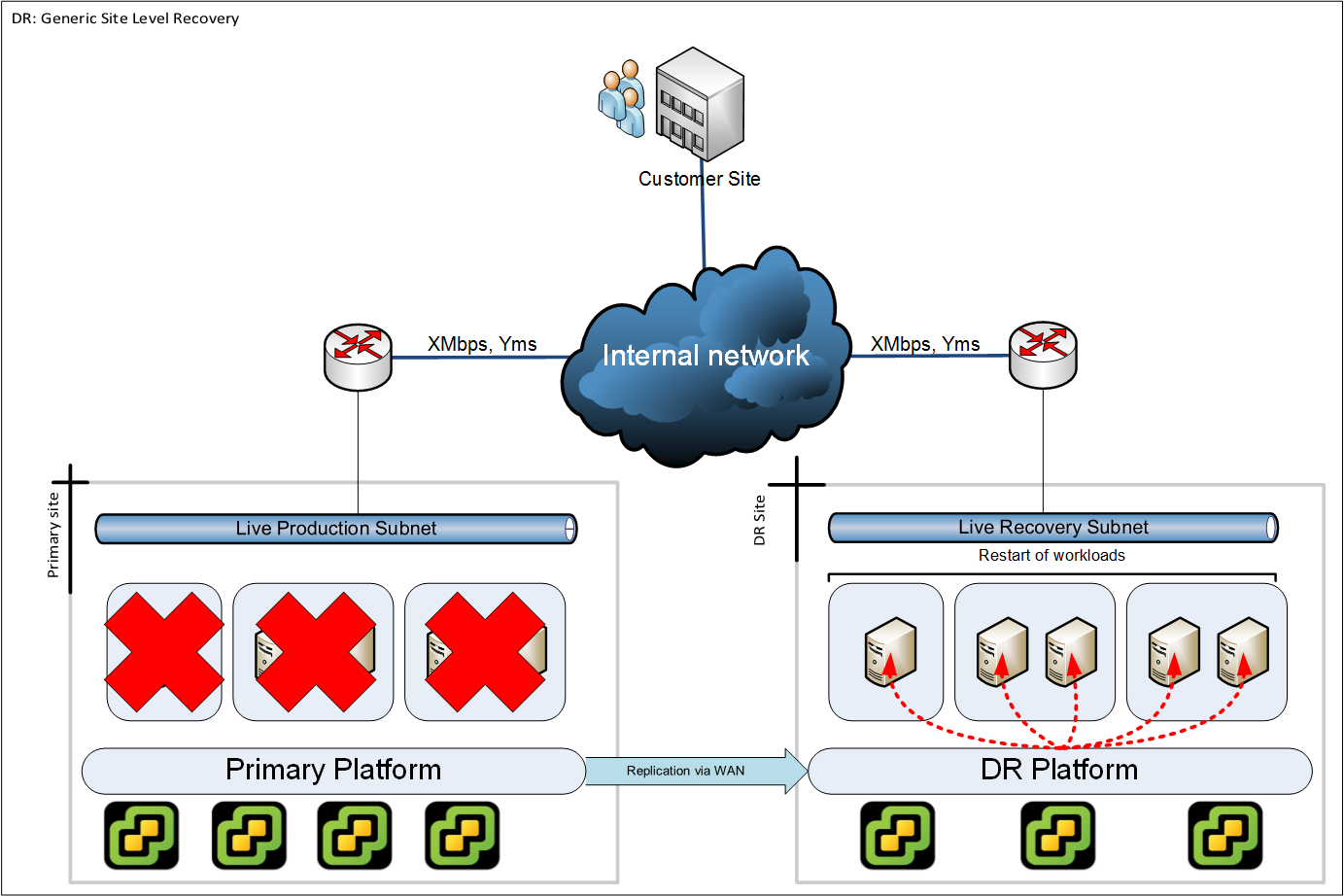
Example: Entire site
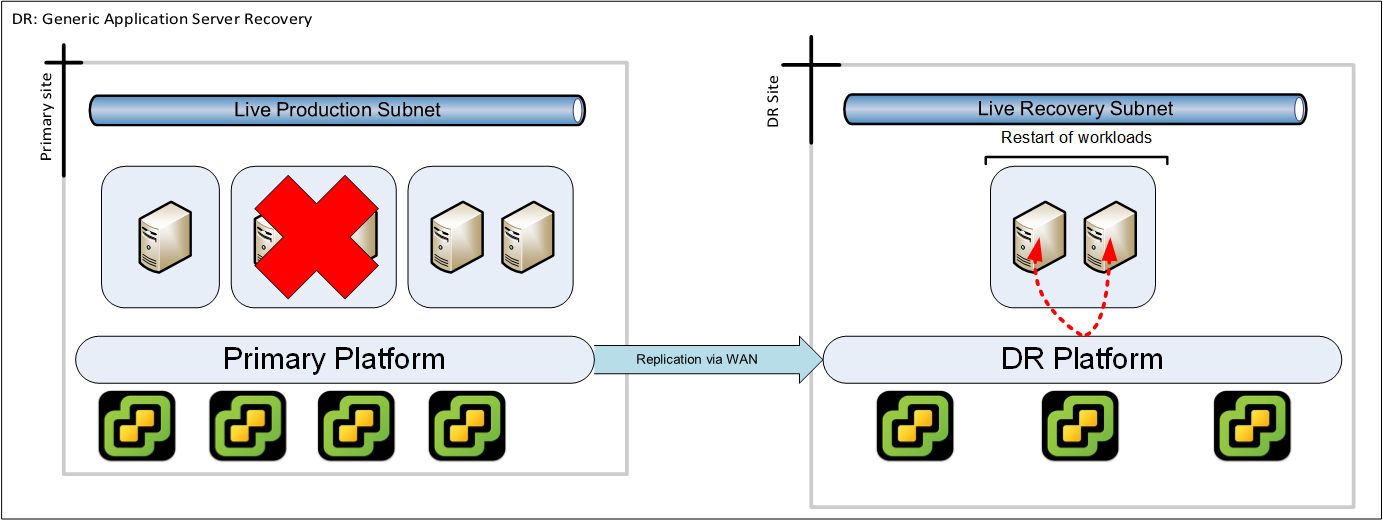
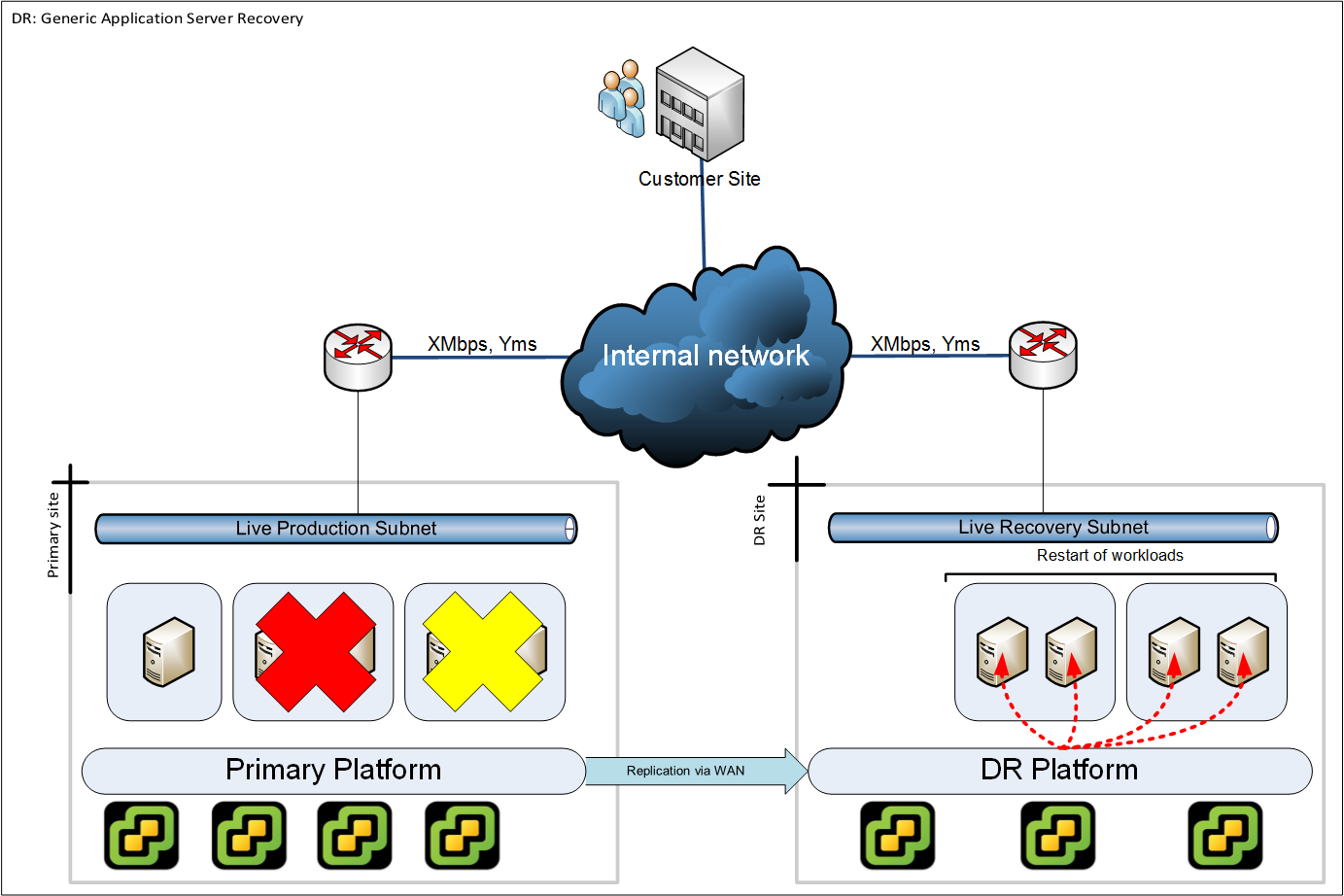
Example: Application server failure
Designed Recovery
Designed recovery in the context of DR extends the scope beyond simple workload recovery (“Get it started on the DR site”).
A designed recovery considers the possible units of protection. For each unit of protection the dependencies are extrapolated in order to determine the method of protection and mechanism of recovery:
Example: Entire site
In this example we suffer a complete site failure. All server workloads get restarted on the DR platform with equivalent network connectivity (bandwidth and latency) to the end users of the IT system.
Example: Application server failure
In this example we suffer the failure of one server group. However as there is a interdependency with another server group we require to failover that as well in order to keep the interaction between the servers at a tolerable latency.
While this is a fictional scenario - unless your designed recovery scenarios consider application server dependencies then you cannot consider anything except an entire site recovery.
Designed recovery also considers the ability to perform (relative to the production infrastructure). If your recovery environment is not as capable as the source production environment then this implies a reduced user experience (if it is expected to run a full production workload, is it?).
There is no doubt that the effort in maintaining a designed recovery is potentially very time consuming - and this is an ongoing process. You can put limits on the design effort by narrowing the scope of desirable recoverability and designing for specific scenarios only.
This implies anything outside of those scenarios are not robustly accounted for within your BCP or DR capabilities.
Delegated Responsibility
Recovering from a disaster is invariably larger than one person. It is therefore useful to remind ourselves that disaster recovery (of IT systems) is a subset of business continuity.
Examples of business continuity:
- Informing affected staff of alternative working arrangements. For example: work from home today, work at the business continuity office.
- Informing affected suppliers of alternative contact details for mail or phone communications.
- Informing affected customers of any disruption to service and what is being done to minimise it.
- Informing affected staff of any disruption to internal systems and setting expectations for recovery. Appointing individuals per location to collate support requests and feed these to a nominated team.
Example of DR:
- Full or partial failover of IT systems to a secondary location.
Typically businesses go through a process of detailing a business continuity plan (BCP). This plan covers a set of prescribed failure scenarios including roles and responsibilities of the organisations staff. The delegation of responsibility should be clear an understood as to who is executing what task within the BCP - and understanding the reporting of progress of completing these tasks.
The BCP (and the recovery promises within) should not be a work of elegant fiction.
Diminishing Risk
Ultimately recovery environments exist in response to risks that if realised will incur downtime. IT sysadmins are forever requested to do everything to maintain “uptime”. Xkcd has a hilarious comic on the subject here:
Recovery environments (and the mechanisms that enable recovery) should endeavour to avoid introducing additional risk to the very environment they are designed to protect.
You might think that this is a given. Take the following theoretical example:
You use a product that takes “snapshots” of live machines - and performs a delta operation to synchronise with the recovery environment.
- For what duration do the snapshots exist?
- What size can the snapshots grow to?
- Is there sufficient free space for them to grow?
- Is there sufficient controls to deal with snapshot problems or is this expected to be handled via other operational processes that the consumer of the product is expected to have in place?
The success criteria of evaluating your recovery enablers should be one that introduces the least risk into your production environment.
Done Right
Recovery “done right” is potentially a time intensive task. The old adage “Your backup is only as good as your last restore” applies equally to disaster recovery.
The successful operation of recovery enablers (data replication for example) does not equate to a guarantee of recoverability.
DR “done right” involves sufficient periodic testing in line with desired recoverability. It requires a quality of testing to ensure your recovery capability is still in line with the designed recovery.
In Summary
At the start of this article I asked - what is DR?
DR certainly is disaster recovery. It’s also everything I’ve discussed here. It could also be much more than covered here depending on where you take the conversation.
It’s very common for business people to take a view that DR is as simple as pressing a button. The bottom line is that the conversation you have about DR is as deep as you make it.