Ireland VMUG January 2014 - Trench Talk

Organised by VMUG and Novosco - the event was held at the MAC in Belfast with good attendance. I was asked to present at the event.
My VMUG event presentation.
Setting the scene:
When approached by John Lennon to present for this event - the subject matter was for me to decide, it only needed to be relevant to a VMware user group. Often when I present the scope of the subject is prescriptively narrow. For example there is only so much variation on a presentation for backup or DR.
I thought on current and recent projects to focus on a subject that should resonate with the expected audience.
At the time of producing my presentation I was engaged with a customer on migrating them to a new vSphere environment. One element of this project involved the new EMC VNX2 (block), quite a contrast from the in-place EMC Celerra. I decided to focus on a component of this project - new storage and a new storage architecture.
This narrowed the subject enough to allowed to me to “deep dive” within the relatively small amount of time for a presentation.
The presentation was titled “Trench Talk: So you’ve got new storage. Now what?”.
I begin by discussing the familiar life sales cycle that eventually leads to system installation and configuration.
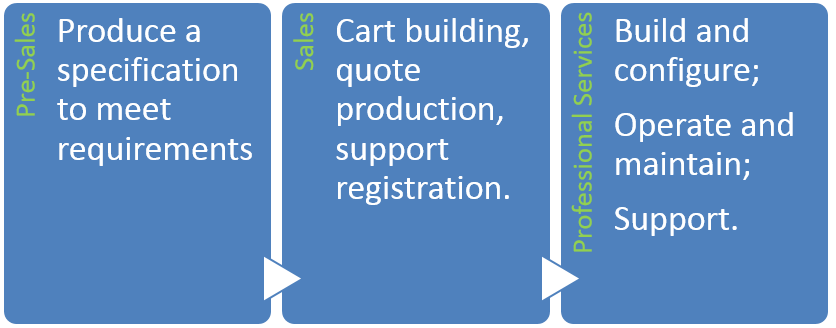
Beginning with pre-sales I summarise how customer storage requirements are often articulated in 8 categories:
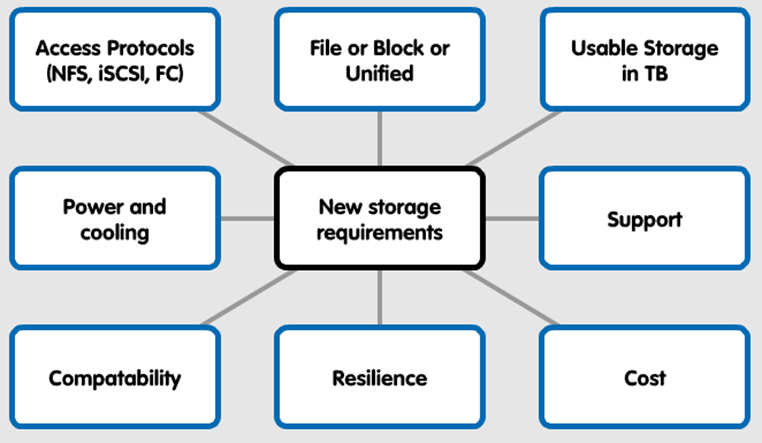
I point out that storage performance is often not explicitly called out, and often it is assumed that a new system with increased usable storage (compared to the old) will bring with it increased performance.
This is not an unreasonable assumption if you are comparing systems of a certain size on a 3-5 year refresh cycle. Often there have been significant gains in architecture and hardware capability for this to be true by default in many cases.
It is however an assumption. My presentation wanted to shed light on this and discuss way of determining the capability of a storage platform in a VMware environment through testing.
Why test?
I discuss four reasons for testing new storage:
- Testing new toys storage platforms can be fun and interesting.
- Establish certainty of platform behaviour.
- Prevent future surprises.
- Set expectations.
We proceed to discuss how I/O testing can help in these four areas.
I/O Testing Methodology
Moving onto what is the core subject material I break I/O testing into three areas:
- Understand your storage architecture and storage design.
- Derive a list of tests to cover all interested scenarios.
- Set expectations on the test results. Compare with actual results. Explain the differences if you can!
Understand your storage architecture and storage design
I’m always reading blog posts. In particularly I love it when people discuss architectural differences and design decisions.
I was reading this post by Itzik Reich who works for XtremeIO within EMC. If you abstract the blog content he is basically discusses that understanding your storage architecture and producing a storage design for performance assurance and availability varies across storage products. Not surprising XtremeIO is the winner of that blog post (bet you didn’t see that coming?).
You can simplify the point further.
Are you designing for the sunny days (assume everything is working all the time, don’t worry about the small chance of failure or its impact) or the rainy days(some element or multiple elements will break, you don’t want any impact to performance)?
The answer to this doesn’t change anything in the actual testing but it will cause different interpretations of results.
Derive a list of tests to cover all interested scenarios.
In order to keep my presentation measured with minutes and not calendars I illustrate with this simple configuration:
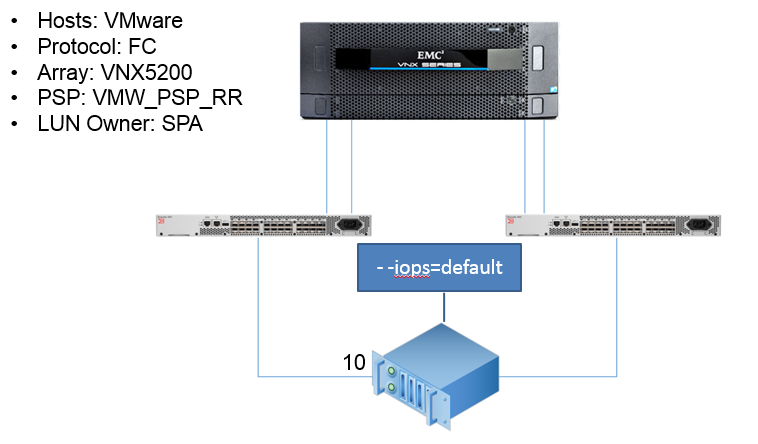
In the above example a typical mid-range array will be pseudo active-active. The LUN is technically accessible by way of 4 paths. Two will be “optimised” and will be preferred. The storage processor owning the LUN will receive all I/O in a round-robin fashion.
Even with this simple configuration and using the default VMware PSP - how many IOPs before the PSP alternates the path used?
If you need to look this up here is a link that will help.
In the case that you are designing exclusively for the sunny day - you won’t be too interested in understanding the what happens in the case of failure.
If you were interested in designing for the rainy day you would need to understand the path utilisation in various failure scenarios. You would have a good start by reading this post on PSP/SATP behaviour.
Whenever we discuss multiple hosts and LUNs bound to multiple SPs it becomes clear that designing for the rainy day can be hard work:
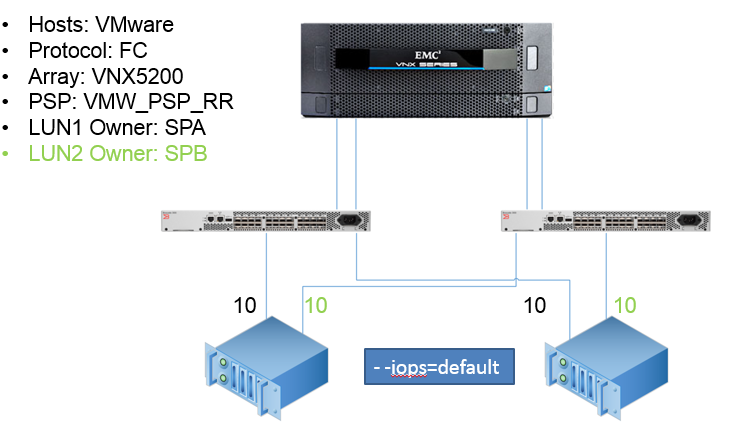
It is therefore necessary to construct a methodology for testing.
Determine the best and worst case performance.
Below is a mind map of a testing methodology I use for determining the maximums and minimums of a given storage target:
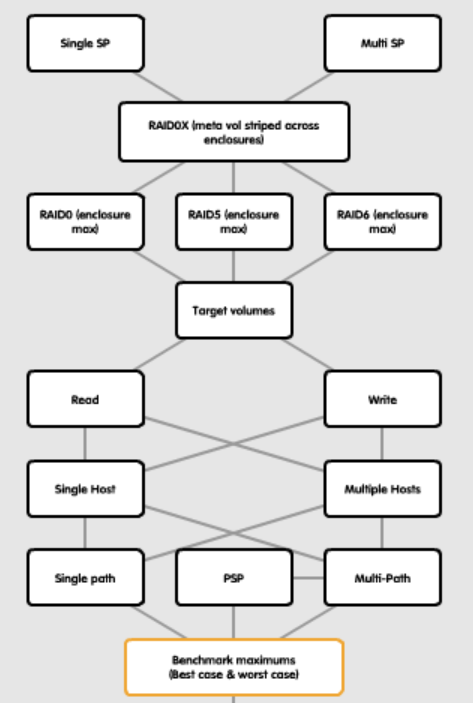
Repeat the same benchmarks with your production configuration. Expect the performance to be less in some respects that the very maximum capability produces. The difference will be attribute to the cost of availability - for example:
- Less disks due to hot sparing means fewer spindles for IOPs.
- CPU overhead due to parity. You could run on RAID 0 - but there would be a lot of rainy days and many tears.
- You may choose N+1 performance availability at the SP (or other) level. Meaning while you not only want to technically survive a failure, you also want no performance degradation.
Testing decisions
By now its accepted that robust testing is both time consuming and requires deep knowledge of the elements involved.
I introduce the concept that even with a methodology the execution of testing can have many permutations.
- Synthetic benchmarking (e.g.Iometer)
- Workload benchmarking (e.g. Jetstress for MS Exchange disk testing)
- Your I/O profile (a complete reproduction of your I/O on the new system)
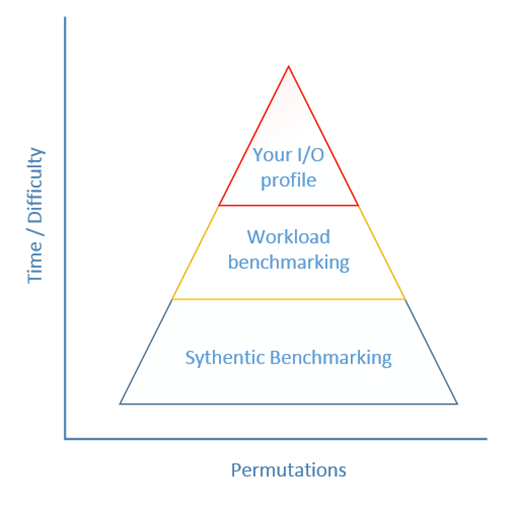
You need to decided what type of testing you are going to perform. There is value in all types but excluding academic interest - the amount of time you can dedicate to the task will likely dictate your choice.
Testing
After laying the groundwork I discuss how the above could be achieved using a VMware fling “VMware I/O Analyzer”. You can find more about VMware flings at their website https://labs.vmware.com/flings.
Lifting some text directly from the fling description articulates why this is a good tool for the job:
- Integrated framework for storage performance testing
- Readily deployable virtual appliance
- Easy configuration and launch of storage I/O tests on one or more hosts
- Integrated performance results at both guest and host levels
- Storage I/O trace replay as an additional workload generator
- Ability to upload storage I/O traces for automatic extraction of vital metrics
- Graphical visualization of workload metrics and performance results
Here are some screenshots using the tool. We used it primarily for synthetic benchmarking.
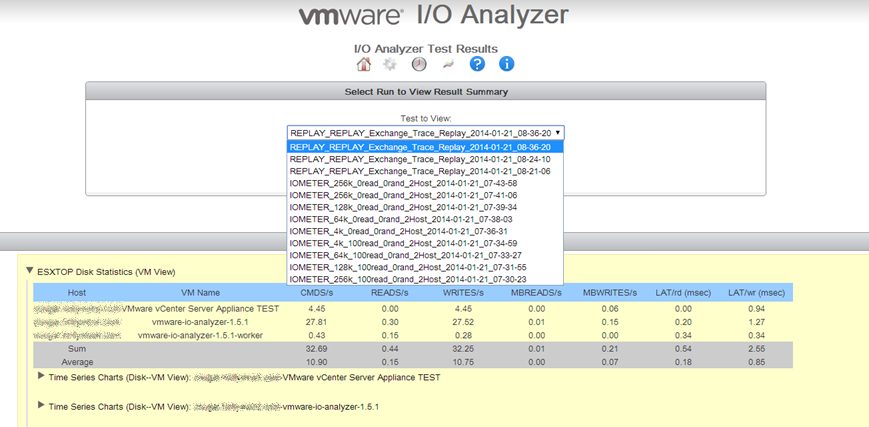
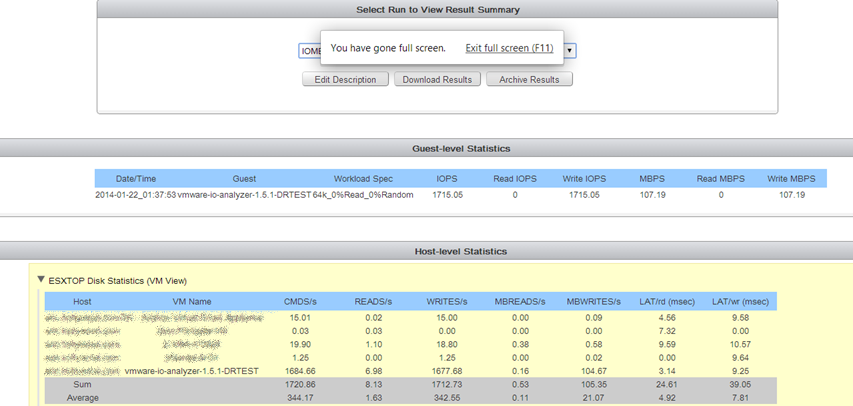
Benchmark results
I have endless excel spreadsheets and graphs from the testing we performed. I picked this one for illustration.
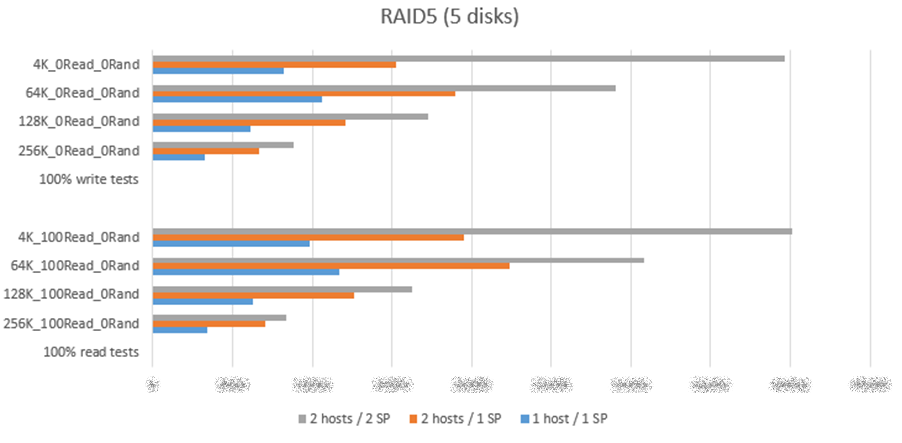
Even without the exact numbers graphed you can make some deductions on the effect of workload size on performance - and the effect of SP failure (compare “2 hosts / 2 SP” vs “2 hosts / 1 SP”).
Using the I/O results in practical scenarios
Understanding your platform capabilities allows you to determine if you are approaching a maximum on your storage platform. Using the information from testing you may construct alarms or reports in your monitoring system of choice. Forewarned is forearmed don’t they say?
Setting expectations
I use backup as a practical use of this type of testing.
Guest level backups can have specific I/O requirements. I quote from an Avamar KB on understanding the performance of a file system backup:
Avamar agent file system backup for example will perform two I/O operations (one for the file attributes, another for the security attributes) for each file that needs to be scanned.
EMC provide maximums for a number of plugins in order to set expectations - around 1 million files per hour for the file system plugin. Not everyone will achieve this - EMC are providing a maximum expectation here where the hardware is not bounding the software. Armed with this information you can determine if your Avamar job performance is bound by the backing storage or other factor.
VM level disk based backup can have fairly predictable I/O patterns:
For example a product producing incremental against a full backup would exhibit random read from the source disk system (CBT map) with sequential write on the target. Based on the configuration of the backup product there will eventually be an incremental roll up which would exhibit sequential read (of the incremental files) and random write (incremental roll up into an existing monolithic backup file) often on the same storage.
I/O testing can therefore help right size a backup solution or right size your expectations.
Closing comments
It was an interesting experience presenting a topic that is relatively theoretical in nature to peers in the local VMware community. The VMUG provides an opportunity to network with peers and foster discussion outside of your normal working environment.
If you can attend future VMUG meetings then I would recommend you do so.
About VMUG
You can find out more about VMUG here: http://www.vmug.com/p/cm/ld/fid=4
You can find upcoming VMUG events here: http://www.vmug.com/p/cm/ld/fid=28